
Page 51 - 电力与能源2023年第六期
P. 51
颜昕昱,等:基于改进 K‒Means++聚类分析的邻户表计错接辨识方法 597
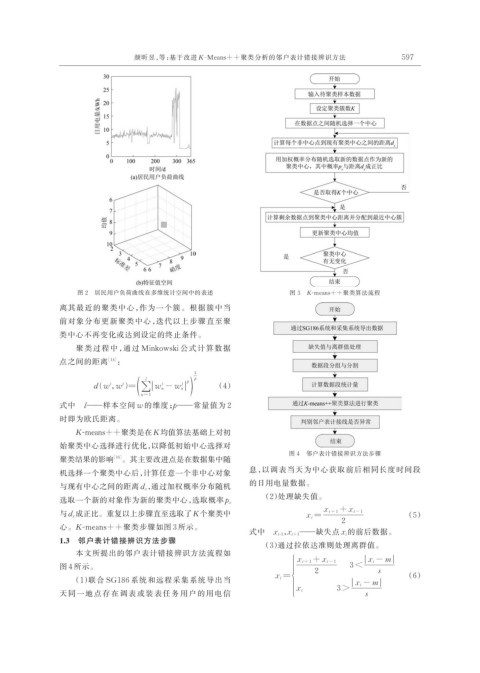
图 2 居民用户负荷曲线在多维统计空间中的表述 图 3 K-means++聚类算法流程
离其最近的聚类中心,作为一个簇。根据簇中当
前对象分布更新聚类中心,迭代以上步骤直至聚
类中心不再变化或达到设定的终止条件。
聚类过程中,通过 Minkowski 公式计算数据
点之间的距离 [14] :
( l p ) 1 p
i
i
j
d ( w ,w )= ∑| w u - w u j | (4)
u = 1
式中 l——样本空间 w 的维度;p——常量值为 2
时即为欧氏距离。
K-means++聚类是在 K 均值算法基础上对初
始聚类中心选择进行优化,以降低初始中心选择对
图 4 邻户表计错接辨识方法步骤
聚类结果的影响 [16] 。其主要改进点是在数据集中随
息,以调表当天为中心获取前后相同长度时间段
机选择一个聚类中心后,计算任意一个非中心对象
与现有中心之间的距离 d x,通过加权概率分布随机 的日用电量数据。
(2)处理缺失值。
选取一个新的对象作为新的聚类中心,选取概率 p x
与 d x 成正比。重复以上步骤直至选取了 K个聚类中 x i = x i + 1 + x i - 1 (5)
2
心。K-means++聚类步骤如图 3 所示。
式中 x i-1,x i+1——缺失点 x i 的前后数据。
1.3 邻户表计错接辨识方法步骤
(3)通过拉依达准则处理离群值。
本文所提出的邻户表计错接辨识方法流程如 | x i - m |
ì x i + 1 + x i - 1
图 4 所示。 ï ï 3 < s
ï ï
x i = í 2 (6)
(1)联合 SG186 系统和远程采集系统导出当 ï ï | x i - m |
ï
天同一地点存在调表或装表任务用户的用电信 ï ï ï x i 3 > s
î